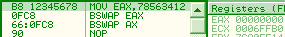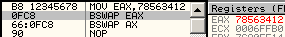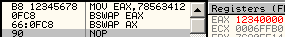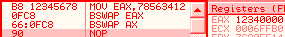|
<< index Android/Java/x86/... opcodes tables PDF tricks Portable Executable x86 oddities Available in: Français x86 odditiesThis page (printable version wiki source) enumerates various oddities of the x86/x64. They are all implemented and tested in CoST. this topic was presented in 2011 at Hashdays (video available) and BerlinSides (screencasts available)
generalregister order
Their logical order is not the alphabetic one: In the CPU, they're encoded in the A, C, D, B order:for example, inc eax is encoded 40, inc ecx is encoded 41, and so on... instruction lengthAn instruction is limited to 15 bytes on recent CPUs (it changed over time): for example, while a nop preceded by 14 useless prefixes is valid,66 66 66 66 66 66 66 66 66 66 66 66 66 66 90: nop => nothingadding one more prefix will reach the limit and trigger an exception:66 66 66 66 66 66 66 66 66 66 66 66 66 66 66 90: ?? => exception However, it's possible to almost reach that limit with legitimate operations:
2e 67 f0 48 818480 23df067e 89abcdef: lock add qword cs:[eax + 4 * eax + 07e06df23h], 0efcdab89h
2e cs:
67 e e
f0 lock
48 qword
818480 add [?ax + 4 * ?ax + ],
23df067e 07e06df23h
89abcdef: 0efcdab89h
f0 2e 66 67 818418 67452301 efcdab89: lock add dword cs:[eax + ebx + 001234567h], 089abcdefh
VirtualPC has been known to be incorrectly ignoring the 15 bytes limit. REX prefix
88EC: mov ah, ch 40 88EC: mov spl, bpl 89D8: mov eax, ebx
4F 89D8: mov r8, r11
40 41 42 43 44 45 46 47 48 49 4A 4B 4F 89D8: mov r8, r11
2E 00F7: add bh, dh 40 2E 00F7: add bh, dh ; 40 is silently ignored 2E 40 00F7: add dil, sil mnemonic length
mnemonic collisionmovsd refers to two different instructions:
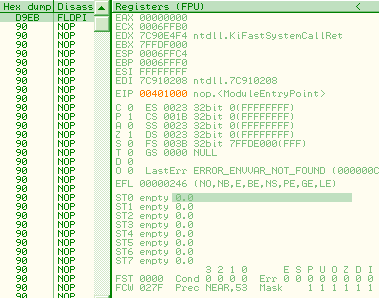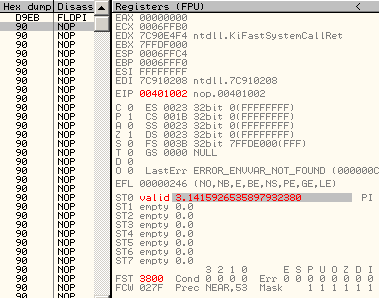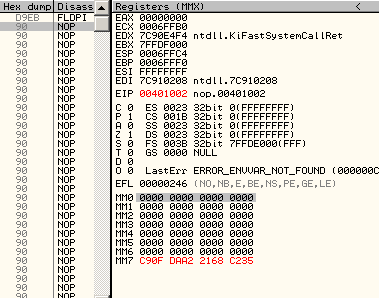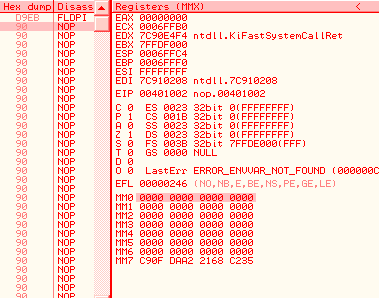
A5 movsd F2:0F 10 C1 movsd xmm0, xmm1 registersMMX and FPUMMX and FPU registers are overlapping, but in opposite directions: 0, 1,2,3... mapped to 7,6,5... Thus, a single FPU operation on st0 will modify fst, st0, but also mm7 (and cr0, under XP). d9eb: fldpi => fst = 03800h st0 = 04000c90fdaa22168c235h mm7 = 0c90fdaa22168c235h cr0 = 080010031h (under XP)
GSOn 32bit Windows, GS is not saved in the execution context: when the OS switches from an application to another, the content of GS is lost. This can be used as an anti-emulator or an anti-stepping: after some time of execution, GS will eventually be reset:
os/tool/vm detectionAt any defined point of execution (EntryPoint, DllMain, TLS...), registers might have different values, depending on the OS.
And, at any point of execution:
These values are currently being collected in the Initial Values page. specificnopnop is an alias mnemonic of 90:xchg *ax, *ax (which does nothing, as no flag are affected by xchg): the whole 90-97 range is actually xchg *ax, <reg32>. 90: xchg eax, eax => eax, eax = eax, eax ;) 91: xchg ecx, eax => ecx, eax = eax, ecx However, xchg *ax, *ax has another encoding, which is not considered a nop. And, on 64 bits, it clears the upper 32 bits of rax. So, not all xchg *ax, *ax are nops. 87c0: xchg eax, eax => rax = eax Hopefully, 90 is truly a nop, even in 64 bits. xchg/xaddxchg, xadd are opcodes that affect both source and target operands (like fxch). Moreover, they can operate on different parts of the same register, which has the potential to break trivial logic analyzers: 0f c0c4: xadd ah, al => ah, al = al + ah, ah aadaad is officially defined to use only 10/0Ah as a default operand, but can just use any other operand. it makes it the first Add and Multiply opcode, as al = ah * operand + al.
ax = 325h d507: aad 7 => ax = 3 * 7 + 25h = 3ah aamSimilar logic for aam:
al = 3ah d403: aam 3 => ah = 3ah / 3 = 13h al = 3ah % 3 = 1 bswap
bswap is officially undefined on WORDS. In reality, it just clears the register, unexpectedly. 66 0fc8: bswap ax => ax = 0 to effectively swap ax contents, one can use 86e0: xchg al, ah cmpxchg*
but some tools might still show obsolete warnings about it.
crc32
The crc32 opcode implements the full algorithm with a single operation, however, it's not the commonly used CRC32 (used in Zip), but actually the CRC-32C (Castagnoli CRC-32), which uses a different polynomial. While it's technically the same algorithm as the 'common' CRC32, it uses a different seed, so it returns different results, thus it's useless for Zip, and all the countless applications of the deflate algorithm. eax = 0abcdef9h ebx = 12345678h f2 0f 38f1c3: crc32 eax, ebx => eax, 0c0c38ce0h It's still usable independently as a checksum, and is actually used in network protocols such as iSCSI, SCTP; it's actually more efficient than the standard CRC32 (when used for recovery purposes), but it's just incompatible. mov
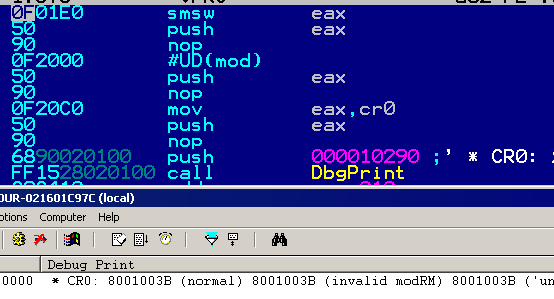
0f 2000: mov eax, cr0 by the usual standards, it should have been decoded as mov [eax], cr0 instead, which would be invalid.
8cc8: mov eax, cs => eax = 0000001bh (xp)
push
Even though selectors are WORDS-sized registers, like standard registers such as AX, they're not pushed on the stack the same way. 1e: push ds => esp = esp - 4 word ptr [esp] = ds 66 50: push ax => esp = esp - 2 word ptr [esp] = ax no other word is changed. movbe
[ebx] = 011223344h 0f 38f003: movbe eax, [ebx] => eax = 044332211h bsf/rbsf/r are undefined when its source is 0. In practice, the target register is not modified. lzcntlzcnt (Leading Zero CouNT) is an opcode created in 2007, only supported by AMD in their Barcelona architecture and later (it's planned in Intel Haswell for 2013, along with its counterpart tzcnt). Recent opcodes would usually trigger an exception when executed on a CPU not supporting them. However, this one is mapped on 0fbd: bsr (Bit Scan Reverse) with an f3 prefix, so it will not trigger any exception on a CPU that doesn't support it:
if you execute: ecx = 35abc80eh (00110101101010111100100000001110b) f3 0f bdc1: if lzcnt is supported by the CPU: f3 0f bdc1: lzcnt eax, ecx => eax = 2 if not: f3 <== ignored prefix 0f bdc1: bsr eax, ecx => eax = 1dh It makes lzcnt an odd exception-less AMD detector (for now): besides, with a null source, lzcnt will return a null value, while bsr will leave the target unmodified. sal
Shift Arithmetic Left (the opcode with modRM 110) is identical to SHL (opcode with modRM 100), and is usually encoded directly as SHL: this means that assemblers always generates the SHL opcode, so SAL is sometimes totally ignored by disassemblers/emulators/... al = 1010b c0f0 02: sal al, 2 => al = 101000b It's informally called SAL, because it's technically a different opcode (in hex), but functionally, it's the same as SHL.
salc
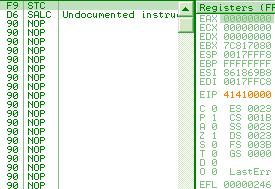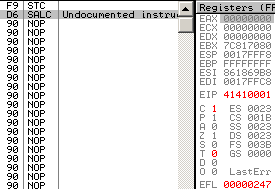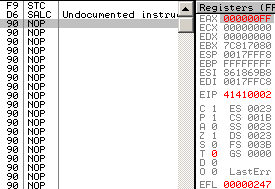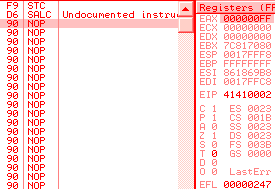
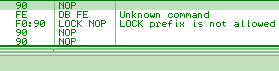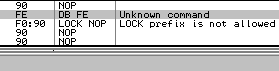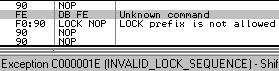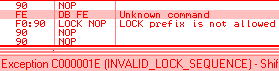
f9: stc d6: salc => al = -1 locklock: works only on memory targets:
and on the following opcodes:
XP bug
lock: is wrongly parsed by Windows XP:
Windows 7 just avoids the problem altogether by triggering an ILLEGAL INSTRUCTION on all invalid opcodes, no matter what, including invalid use of LOCK: prefix. No parsing, no mistake ! fef0: ?? => INVALID LOCK SEQUENCE (XP, bug) ILLEGAL INSTRUCTION (W7) Windows 7 bugOn the other hand, lock:prefetch is wrongly handled by Windows 7. It's an illegal instruction, and while it triggers correctly an INVALID LOCK SEQUENCE exception on XP, it doesn't trigger any exception under Windows 7. It's invalid, so can't be executed, yet triggers no exception, so it just hangs, like an infinite loop, but without crashing. even more exceptional, the OS patches the opcode: executing f0:0f 0d 00 turns it into f0:0f 1f 00. smsw
0f 01e0: smsw eax => eax = 8001003b (XP) str/sldtLike smsw, they work on DWORD or WORD on registers, but only on WORD in memory. 0f 00c8: str eax => eax = 00000028h (XP) 66 0f 00c8: str ax => ax = 0028h (XP) 0f 0008: str [eax] => word ptr [eax] = 0028h (XP) it's the same for sldt. testtest <r32>, <imm32> has an alternate encoding that is sometimes forgotten, as it's never generated by compilers or assemblers. f7c8 44332211: test eax, 11223344h IceBP
f1: IceBp => SINGLE STEP (80000004h) exception rdtscp
rdtscp is a recent opcode that just returns the usual rdtsc result to eax/edx, and also changes ECX: it's loaded with the low-order 32-bits of IA32_TSC_AUX MSR ... which means most of the time, 0. 0f 01f9: rdtscp => edx:eax = <rdtsc> ecx = 0 hint nop
0f1980 00000080: nop [eax + 8000000h] => nothing
branch hints
16b flow
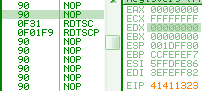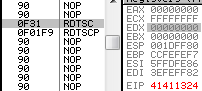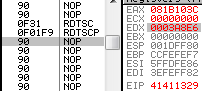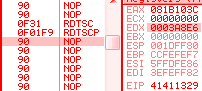
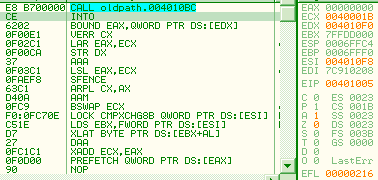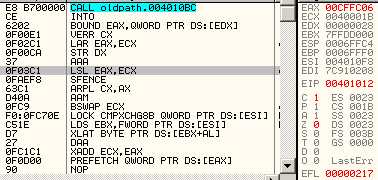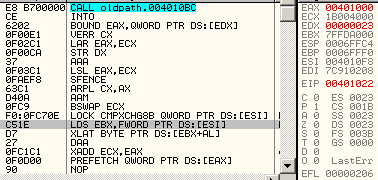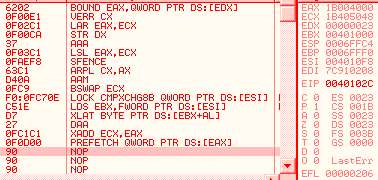
68 00104000: push 401000h 66 c3: retn => eip = 00001000h esp = esp - 2 obsolete opcodesThere are many opcodes that are never (or in extreme cases) generated by compilers nowadays, that still fully work under modern CPUs. The list is long: xadd, aaa, daa, aas, das, aad, aam, l*s, bound, arpl, xlatb, lar, verr*, cmpxchg*, lsl... For example, Here is some code, fully working under a modern CPU, but obfuscated by its obsolescence: into bound eax, [edx] verr cx lar eax, ecx str edx aaa lsl eax, ecx sfence arpl cx, ax aam bswap ecx lock cmpxchg8b [esi] lds ebx, [esi] xlatb daa xadd ecx, eax prefetch [eax]
future opcodesIntel Haswell will introduce very useful opcodes (on general registers) such as:
andn eax, ebx, ecx => eax = !ebx & ecx which is functionally equivalent to 8086 instructions (from 1978): 89d8 mov eax, ebx f7d0 not eax 21c8 and eax, ecx
x6432 bits zero extendingIn 64 bits, opcodes are zero-extending on 32 bits registers. thus, while fec0: inc al 66 ffc0: inc ax ffc0: inc rax all do what you would expect. but on the other hand, 48 ffc0: inc eax resets the upper 32 bits of RAX. switching between 32b and 64b modesOn a 64 bits CPU, the cpu can just change from/to 32b mode by jumping to a properly defined selector. In short, changing the number of bits just mean jumping to a different value of CS. For example, in a 64b version of windows, selector 33h is for 64b. Jumping to it from a 32b process, then jumping back, will switch to 64b, then back to 32b. It's as simple as that. <32b>
call far 33h:_64b
<32b>
_64b:
<64b>
...
retf32+64Since there are some opcodes specific to 32 bits mode (arpl, ...), and others specific to 64 bits mode (movsxd, ...), the same hex data can lead to completely different disassembly, just because CS is different at the start.
acknowledgements
Other resources
====<< index (opcodes tables/pdf tricks/Portable Executable/x86 oddities) | ||||||||||